计算机科学中最令人着迷的问题常常是那些最基本的问题,时间就是其中之一。尽管相对论时空观的确立远早于现代计算机的诞生,然而大多数开发者在面对分布式系统时,仍然用牛顿时代的心智看待时间。他们并不清楚自己将要面对什么:将系统构建于幻象之上。本文探讨了分布式系统中时间的定义,并列举了现实世界中的工程案例。

时间是什么
爱因斯坦说时间是幻象;马赫说以人类之力无法用时间度量事物变化,相反我们只是在用事物变化来表现时间;牛顿认为时间是存在于宇宙之中的绝对刻度;莱布尼兹和康德认为时间不过是一种心智概念,让人类得以对事件进行排序和比较。关于时间的争论已经延续了数千年并将继续延续下去。还好所有的模型都是错的,但有些是有用的(all models are wrong, but some are useful)。我们可以寻找对编程来说有用的抽象,并将系统构建于之上。
狭义相对论告诉我们宇宙中不存在全局的绝对时间。"now"没有意义,除非我们知道"where"。由于光速不变,不同的观察者在相对运动时度量的是不同的时间。也因为光速是信息传输的速度上限,观测者间就绝对时钟达成一致变得几乎不可能。
等等,难道不能假设我们处在一个惯性系中吗?我们的计算机位于地球表面,主要在重力场作用下,以远低于光速的速度围绕太阳运动。然而在现实世界中,计算机网络以光缆连接,信息在光缆中传输的速度远低于光速。面对分布式系统中的包传送延迟,我们遇到的情形跟相对论所讨论的抽象是类似的。在分布式系统中建立绝对时钟仍然是让人头疼的问题。
A system is distributed if the message transmission delay is not negligible compared to the time between events in a single process.
–Leslie Lamport
开发者对分布式系统常常抱有以下错误假设:
- 网络是可靠的
- 延迟为零
- 带宽是无限的
- 网络是安全的
- 拓扑是不变的
- 总有个管理员
- 传输开销为零
- 网络是同质的
现在这个列表需要再加一项:时间是牛顿式的。
时间即秩序之源
我更喜欢莱布尼兹和康德的时间观,因为对计算机系统来说,多数情况下真正重要的是事件的顺序(Order of Events)。我们今天所使用的计算模型和编程抽象主要基于图灵机:通过按顺序执行一系列的操作指令来进行计算。顺序至关重要。而在分布式系统中,如果我们能确保不同的系统按相同的顺序运行相同的指令,我们就可以把机器集群当做单台计算机来对待——这也是保证正确性最容易的方式。

实践中我们通常用时间戳(Timestamp)对事件进行标记。常用的Unix时间戳反映了Unix纪元(January 1st, 1970 at UTC)以来的总秒数。有了时间戳,我们可以更好地对事件进行排序和推理。
从网络层到传输层的各种拥塞、排队、超时与重传都有可能导致应用层的数据包乱序抵达。通过时间戳,我们可以将送达的消息先放入缓冲区,等待更多消息到达,按时间戳排序后再按顺序执行。在消息驱动架构中,我们常常需要对消息设置一个过期时间。当消息到达了过期时间而没有被消费时,消费者就可以忽略并转发到死信通道。很多并发控制与冲突检测机制也依赖于时间戳。通过给数据标记时间戳作为版本号,配合CAS可以很容易实现乐观锁,在合适的场景下可以极大地提升系统吞吐量。
分布式系统的正确性离不开时间。时间即秩序之源(time is the source of order)。
论因果之不可知
一个分布式系统可以描述为一个特殊的具有多个由网络互联的处理器的串行状态机。如果我们能对全部输入事件进行全排序,就能够实现任何由网络互联的处理器组成的状态机,也就可以实现任意的分布式系统。全序事件是分布式系统的圣杯。
既然提到了全序,这里来复习一下离散数学。全序(total order)可以描述为集合X上反对称的(antisymmetric)、传递的(transitive)和完全的(connex)二元关系。也就是给定集合X,下列陈述对所有集合中的元素a,b,c都成立:
if a<=b and b<=a then a=b (antisymmetric)
if a<=b and b<=c then a<=c (transitive)
a<=b or b<=a (connex)
关于connex可以理解为:集合中的任何一对元素都是可相互比较的。
跟全序相对应的是偏序(partial order)关系。偏序关系同样满足反对称性和传递性,不同的是偏序只满足自反性(reflexivity)而不满足完全性(connex)。
a ≤ a (reflexivity: every element is related to itself)
也就是说在偏序关系的集合中,部分元素是不可比较的。
大家比较熟悉的例子是版本控制系统中(e.g. Git)的分支。对于单分支主干开发来说,每个commit的先后关系都是可比较的,满足全序关系。一旦我们使用了分支开发,不同分支上的commit将只满足偏序关系。全序关系相比偏序关系更容易推理(reasoning)和维护,这也是为什么我们推崇TrunkBasedDevelopment胜过FeatureBranch。
狭义相对论告诉我们时空中的事件不存在一个始终如一的全序关系,不同的观察者对于两个事件谁先发生可能有着不同的看法。当且仅当事件1和事件2处于一个光锥(light cone)中,我们才能确定先后关系。因果存在于光锥之中。
分布式系统也是如此。进程内部发生的事件可以视为光锥之内,我们可以得到事件的本地顺序。而跨越网络的进程间,因为消息传递的延迟已经大大超出了进程内时延,事件间并不存在天然的全序排列。在日常生活中简单的先后因果关系,在分布式系统中并不是那么显而易见。洞悉了这一切的Leslie Lamport定义了分布式系统中的"happen before",并以此获得了图灵奖。
在保持通信的状况下维护分布式系统中的因果关系并非不可能,只是非常昂贵。接下来我会介绍在工程实践中,人们是如何捕获事件的全序关系的。
现实世界的时钟
如果说时间是事件的序列,时间戳是标记事件的手段,那时钟(clock)的本质是捕获时间戳的整数计数器。无论是日晷还是石英钟,都是通过合成自然现象并转换成相应的整数值(时钟时间)。在分布式系统中我们所使用的时钟一般分为以下三种
- 本地时钟(local clock)
- 全局时钟(global clock)
- 逻辑时钟(logical clock)
本地时钟
获取时间最简单的方式就是使用本地时钟。现代计算机一般内置有石英晶体,石英晶体通电后会以一定频率震荡,成为操作系统本地时钟的来源。值得注意的是石英晶体的谐振并不是恒定的,其频率受服务器温度影响比较大——温度升高时震荡频率升高,温度降低时震荡频率降低。尽管操作系统例程会对时钟进行调整,降低频率变化带来的影响,但在没有外部时钟同步的情况下,石英钟的漂移(drifts)是不可避免的:时钟总会比预期快一点或慢一些。Google假设其服务器时钟漂移为200 ppm(百万分之一),也就是说每天对时钟进行重新同步的话,时钟的漂移为17秒。
然而对于那些不需要获得全序事件的分布式应用来说,本地时钟已经够用了。不管时钟如何漂移,在进程内事件的偏序关系是可以得到保证的。如果把浏览器当做分布式应用,本地时钟是可以满足JavaScript的Event Loop的。当然,前端程序员都明白不能用一台机器的时间去跟另外一台机器的时间对比,持久化业务对象时最好不要使用浏览器生成的时间戳。"总是使用服务器时间"是前端程序员们对全序事件最朴素的理解。
全局时钟
在保持通信的状况下,维护一个全局时钟是可能的。解决这个问题有两个思路。一种思路是通过观测精度较高的物理时钟,并通过网络通信维持不同节点时钟的同步。另一个等价的解决方案是,在分布式系统中获得唯一(unique)且自增(incremental)的id。既然我们可以把时钟当成计数器,那无论是物理时钟还是自增id都可以帮我们标记全序事件。
NTP是生产中最常用的时钟同步协议。对系统管理员来说,维护系统时钟这件事基本等同于“打开NTP”。NTP被设计为分层(Stratum)的时间源系统,较低的层级有更高的时间精度,Stratum 0留给那些最高精度的计时设备。NTP通过轮询机制来调整本地时钟。轮询频率太高会给网络带来太大压力,过低则会产生较大的时钟偏移。因此轮询频率是NTP时间精度的一个约束因素。此外NTP的同步受到网络延迟影响,数据包在网络中传输本身需要时间,在网络拥堵时延迟甚至会达到秒级。实践中还经常会遇到NTP服务器/客户端配置错误、硬件虚拟化中断导致的时钟跳跃、人工修改系统时钟导致偏移过大从而拒绝同步等问题。NTP的应用并非一帆风顺。但对于时间精度要求不高的业务应用来说,NTP已经是足够好的选择了。

而对于精度要求较高的系统来说,NTP可能引发一些问题。像Cassandra这样leaderless的分布式数据库往往使用最后写入为准(LWW)的策略来处理写冲突,较新的时间戳会赢得胜利。在NTP的精度下,有可能出现旧数据覆盖新数据的问题。
Google在追求服务器的时间精度上不遗余力,其代表作是Google Spanner的TrueTime API。Google Spanner是一个分布式数据库,以实现了全球范围(global scope)的分布式事务而知名。TrueTime API提供了全球范围有意义的提交时间戳,从而让Spanner得以对分布式事务进行序列化排序。
TrueTime API的底层依赖GPS和铯原子钟,二者的失效模式不同,通过合成可以得到更高精度的时钟。每个Spanner数据中心都配有铯原子钟和多台GPS接收器,每台服务器都有timedemaon从附近的多个timemaster获得时间参考值。很重要的一点,Spanner接受时间是不确定的,因此从TrueTime API获得的时间不是具体的数字而是一个置信区间。

当然不是所有组织都有预算给自己的机房搞一套GPS和原子钟。前面也有提到,这个问题的另一个等价答案是为你的分布式系统生成一系列唯一递增的id。相信不少做业务系统的同学都遇到过这个问题,如何实现一套自增(最好是定长的)业务流水号?(uuid不满足自增)
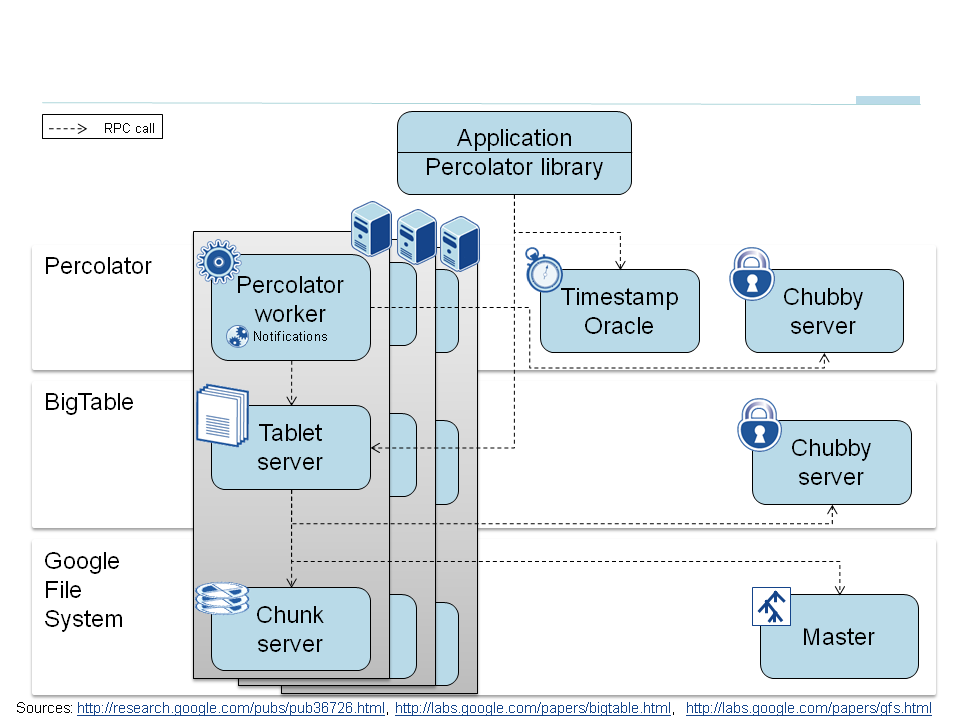
最简单的方式是由一个中心化的节点统一生成和分配id。听起来不那么"分布式"?多数情况下这是最简单的方式,即使在Google量级的规模下也绝对是值得考虑的方案之一。Google的Percolator就通过Timestamp Oracle Service来提供全局唯一的时间戳。当然,这种发号取号的方式给单点容错的压力还是挺大的,服务一般会通过预生成id和多级缓存来降低latency提升QPS。
我们可以把id生成做得更分布式一些,不依赖某个中心节点。今天多数的分布式id生成算法大都启发自Twitter的Snowflake,其思想很简单,把时间戳、机器编号(一般用机房+MAC地址)和毫秒内自增id结合在一起。该算法分布在不同的机器上执行,得到统一无碰撞且满足需求的自增id。其实现也并不复杂,通过位操作可以在短时间内生成大量可用id。
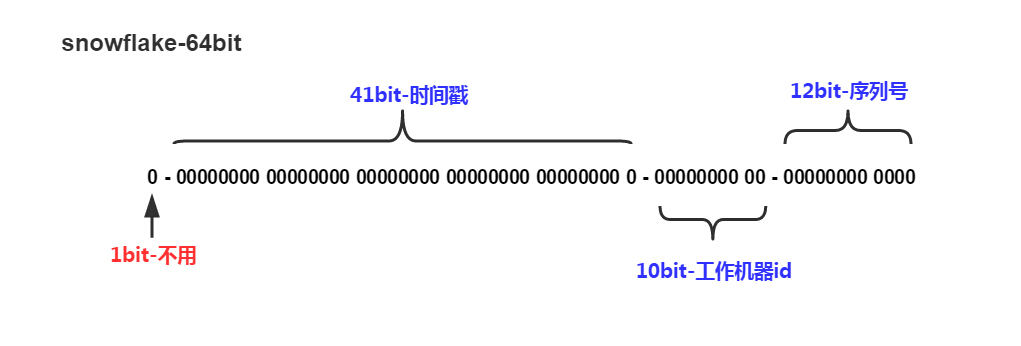
Snowflake的一个问题在于受到时间回拨影响,如果系统时钟回拨可能会生成重复id。因此实践中一般会把NTP配置为时钟不回拨模式。
逻辑时钟
如果说时间的关键是事件的顺序,时钟不过是计数器,让我们把这个观念向前再推一步:物理时钟真的重要吗?由此我们可以引入逻辑时钟(logical clock)的概念:clock是事件分配编号的方式,编号就是事件发生的时间。在这个系统里,时钟可以通过没有任何计时机制的计数器来实现。以下就是著名的Lamport Clock算法:
- 每个进程维护一个独立的计数器
- 当事件在进程内发生,
计数器+1 - 如果事件是发送消息,
计数器+1并在消息中带上该计数器 - 如果事件是接受消息,计数器=
Max(本地计数器,消息中计数器)+1
在进程内发生的偏序事件是很容易确认因果关系(happen before)的,而Lamport Clock通过显示区分发送事件和接受事件,并在消息中携带计数器的方式让跨节点排序成为可能。
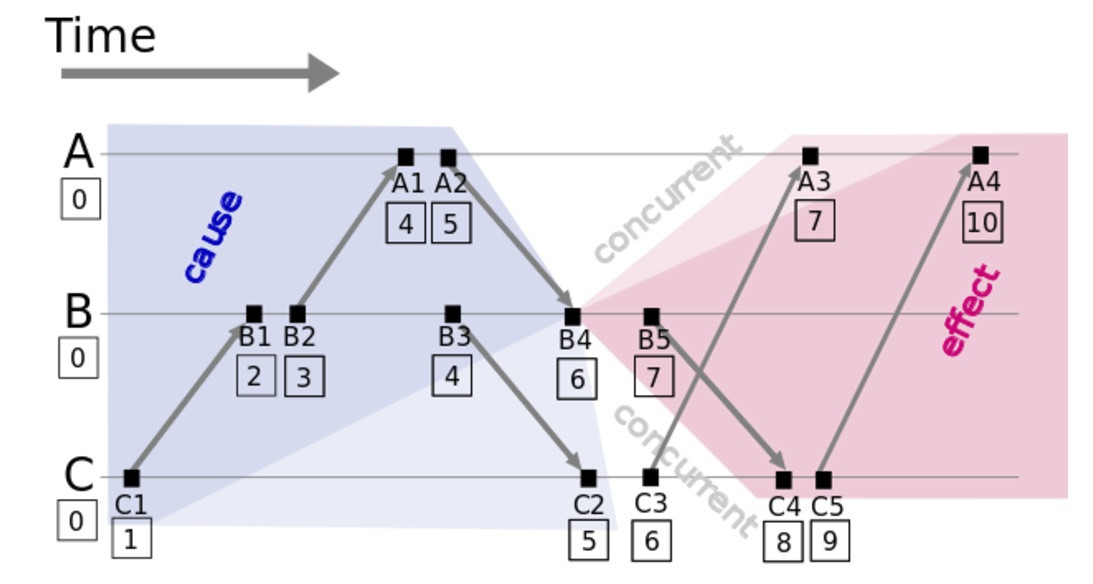
- 以图中的B4为例,左侧深蓝色区域时间戳小于B4,就是B4的因(cause);右侧深红色区域时间戳大于B4,就是B4的果(effect)。
- 白色区域的C3时间戳跟B4相同,跟B4无因果关系,可以理解为并发(concurrent)。注意即使在物理时间中C3和B4不是同时发生的,在Lamport Clock中因为时间戳相同,仍表现为并发。
- 在Lamport Clock中若时间a发生在事件b之前
(a->b)可推出a的时钟小于b的时钟C(a)<C(b),但反过来C(a)<C(b)并不能保证(a->b)。上图中的C2在物理时间上可能跟B4同时发生甚至晚于B4,在Lamport Clock时间戳上却小于B4。Lamport Clock并不能很好地刻画并发关系。
我们可以对Lamport Clock进行增强,就得到了向量时钟(Vector Clock)。Vector Clock维护了N个逻辑时钟的数组[C(A), C(B), C(C)...],每个逻辑时钟对应一个进程。每个进程负责维护自己所对应的逻辑时钟:
- 当事件在进程内发生,进程在Vector中所对应的
计数器+1 - 如果事件是发送消息,将本地的Vector Clock和消息一起发送
- 如果事件是接受消息:将Vector中的每个元素都更新为
Max(本地计数器,消息中计数器); 将当前进程所代表的逻辑时钟+1
在Vector Clock中我们规定:
- 事件i和事件j所对应的Vector Clock中,每一个进程p所对应的逻辑时钟都满足
Vi[C(p)]<Vj[C(p)],则事件ihappen before事件j。 - 否则事件i和事件j是并发关系(或称没有因果关系)。
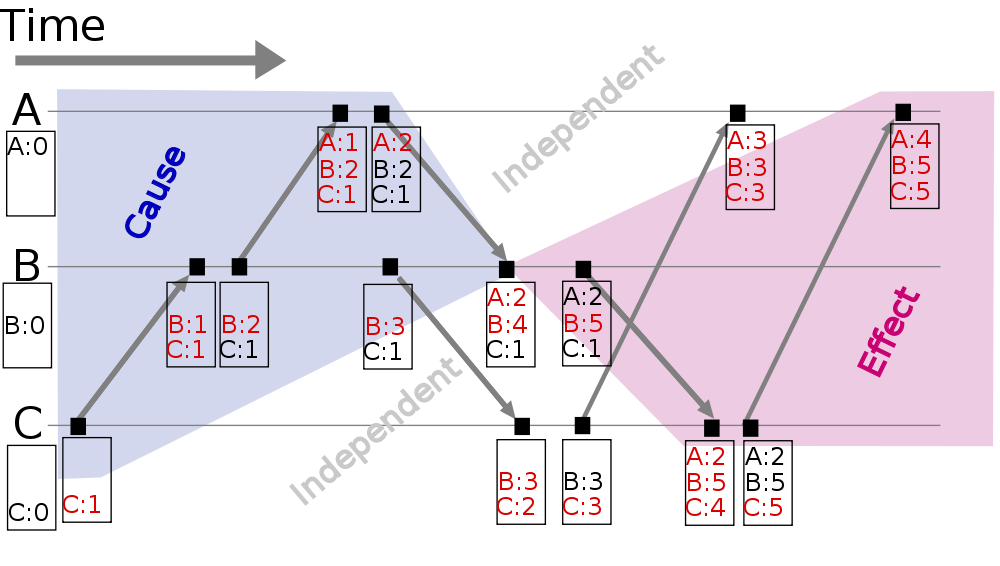
通过Vector Clock可以很容易地判别影响{A:2, B:4, C:1}的事件。
在工程中,像Amazon Dynamo和Riak等数据库都大量使用了Vector Clock进行对象版本管理和冲突检测。通过利用逻辑时钟可以很好地避免物理时钟精度和通信延迟所带来的限制。
区块链中的时间
我经常开玩笑说真正hardcore程序员要么为时间编程,要么为金钱编程,区块链兼具两者。而对时间和金钱进行建模抽象的确能有效提升程序员的编程能力,每个程序员的职业生涯都应该至少有以下经历:会计系统、时间序列分析、日历...
币圈信徒常常对区块链的时间戳赋予过于神圣的意义,然而了解区块链运作机制的人们都知道,时间戳的象征和提示(hint)意义远大于其精确度:在一个去中心化的系统里,怎么可能得到一个绝对准确的时间嘛。区块链的设计者们深知这一点,并给时间戳留下了足够的冗余。在比特币的block timestamp中,如果时间戳大于前11个区块的中值时间并小于网络调整时间+2小时,就可以被接受为有效时间。这导致比特币区块的时间戳并不完全按顺序排列。以太坊则明确规定区块的时间戳需要大于前一个区块且小于2小时的偏移。
最具启示意义的莫过于Bitcoin的创始区块,名为中本聪的神秘男人在coinbase留下了泰晤士报当天的头版标题:"The Times 03/Jan/2009 Chancellor on brink of second bailout for banks"

至于genis block的timestamp是1月3号还是1月9号并不重要了,通过事件排序我们可以确定创始区块一定诞生在2009年1月3号的泰晤士报发行之后。
时间的关键是Order of Events。
洞悉这一点后,你会发现区块链上真正重要的不是时间戳,而是交易的顺序。在一个点对点的电子现金系统中,正确性基于以下两点:
- 你不能花你还没收到的钱
- 你不能花你已经花出去的钱
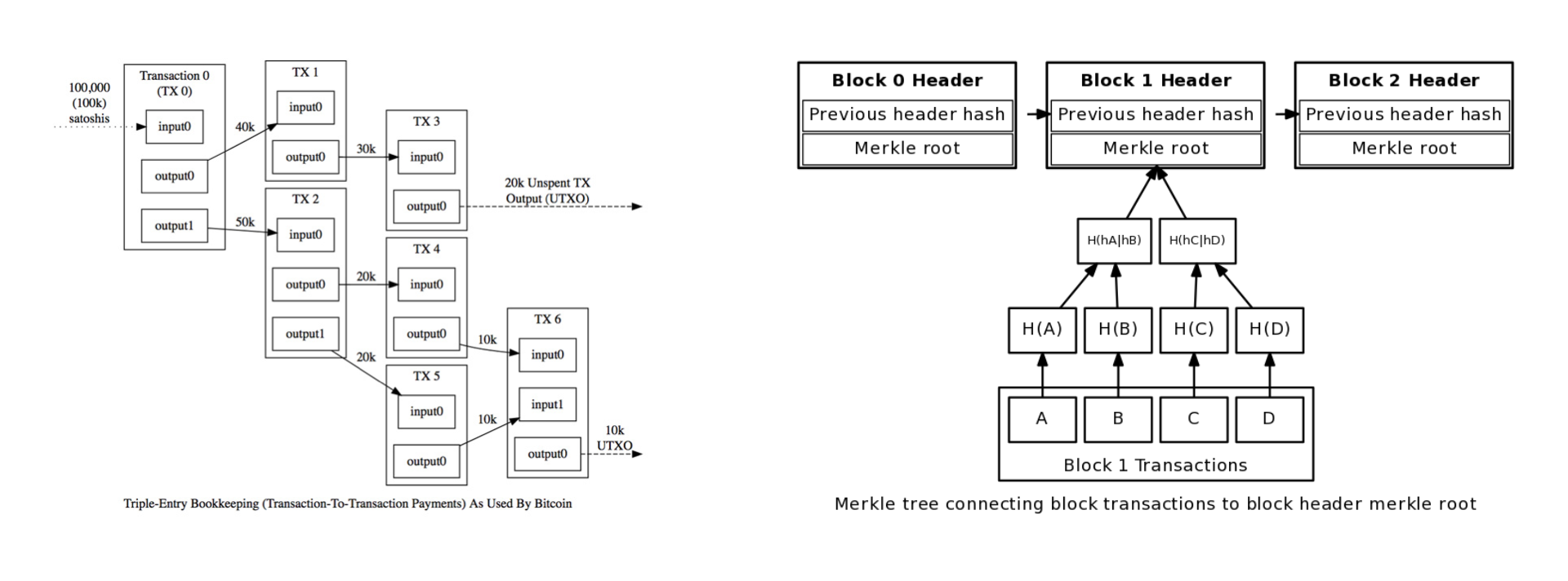
比特币通过UTXO(Unspent Transaction Output)确保了每笔现金花费必有输入,再加上哈希指针和区块链的结构,确保了交易和交易之间以确定性、不可变的顺序连接在一起。于是我们得到了一个全序的交易序列。
除了验证交易,那些矿工节点真正的工作意义是什么呢?为交易排序并打包成区块。所以即使像Hyperledger Fabric那样的联盟链,去掉了挖矿,将PoW替换成Kafka那种甚至不能保证拜占庭容错的共识,却仍然在架构中保留了Ordering Peer的building block,就是为了给交易排序和打包。
而对于那些迈向DAG的下一代分布式账本平台来说,在获得更大吞吐量的同时,也失去了全序事件所带来的简洁性和易推理性。
小结
我一直觉得时间个有趣的主题,只是疏于动笔。40年前Lamport就已经为我们指明了分布式系统和相对论之间的联系,剩下要写的就是围绕这一主题把理论和工程案例联系在一起。这个话题始于跟曲哲、鄢倩和静源在饭桌上一次就相对论的讨论。年底的技术大会留给我一个slot讲区块链——本来想以时间出发讲区块链的确定性(deterministic)——还是跑题扯了一通相对论,也借机把分布式系统中的时间梳理一下。
经历过很多客户和同事在进行分布式系统的设计时(甚至有时候他们自己没意识到是在做分布式),总抱有这样那样的侥幸:我可以保证系统的正确性/可靠性/一致性因为我用了更好的硬件/中间件/分布式事务框架...遗憾的是物理定律并非如此。时间是一个很好的例子,比较纯粹,又足以揭示真实世界的复杂性。我们必须理解并接受分布式世界中的复杂性,并将其融入系统的设计和构建中。
扩展阅读
其他没有在正文直接引用但我实际参考了更多的文章有:
- Time, Clocks, and the Ordering of Events in a Distributed System, Leslie Lamport, 1978
- Distributed system for fun and profit: time and order, Mikito Takada, 2013
- Time is an illusion, George Neville-Neil, 2016
- There is No Now, Justin Sheehy, 2015
- Detecting Causal Relationships in Distributed Computations: In Search of the Holy Grail, Schwarz & Mattern, 1994
- Why Vector Clocks are Easy, Bryan Fink, 2010
- Why Vector Clocks Are Hard, Justin Sheehy, 2010